
Building an Ollama-Powered GitHub Copilot Extension
GitHub Copilot
Table of Contents
A few months ago, I wrote about creating your first GitHub Copilot extension, and later discussed this topic on the GitHub Open Source Friday live stream.
Creating a GitHub Copilot Extension: A Step-by-Step GuideBuilding off the Copilot extension template I made based on that initial blog post, I decided to take a crack at an Ollama-powered GitHub Copilot extension that brings local AI capabilities directly into your development workflow.
What is Ollama?#
Before diving into the extension, let’s briefly talk about Ollama. It’s a fantastic tool that lets you run large language models locally on your machine. Think of it as having your own personal AI assistant that runs completely on your hardware – no cloud services required. This means better privacy, lower latency, and the ability to work offline.
That said, you’re running off your own machine, which means you don’t need to pay for Ollama.
Introducing the Ollama Copilot Extension#
The Ollama Copilot extension demonstrates the potential of combining local AI processing with GitHub Copilot chat. While still under development, it showcases several powerful features:
Key Features:
- Local AI Processing: All AI operations run on your local machine through Ollama (for the Copilot extension, not Copilot Chat overall)
- CodeLlama Integration: Leverages the CodeLlama model, which is specifically trained for programming tasks
- Low Latency: Direct communication with a local AI model means faster response times and no cost to you. This is true, but only in the context of running this Copilot extension in development mode.
While Ollama enhances privacy by running locally, it’s important to note that GitHub Copilot still uses cloud-based models, so complete privacy isn’t guaranteed in this context.
Core Extension Structure#
The extension is built using Hono.js, a lightweight web framework. To get things running, you can configure a couple of environment variables or go with the defaults.
export const config = { ollama: { baseUrl: process.env.OLLAMA_API_BASE_URL ?? "http://localhost:11434", model: process.env.OLLAMA_MODEL ?? "codellama", }, server: { port: Number(process.env.PORT ?? 3000), },};The main endpoint handles incoming requests from GitHub Copilot, verifies them, and streams responses from Ollama:
app.post("/", async (c) => { // validation logic
// ...
return stream(c, async (stream) => { try { stream.write(createAckEvent());
// TODO: detect file selection in question and use it as context instead of the whole file const userPrompt = getUserMessageWithContext({ payload, type: "file" });
const ollamaResponse = await fetch( `${config.ollama.baseUrl}/api/generate`, { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ model: config.ollama.model, prompt: userPrompt, stream: true, }), } );
if (!ollamaResponse.ok) { stream.write( createErrorsEvent([ { type: "agent", message: `Ollama request failed: ${ollamaResponse.statusText}`, code: "OLLAMA_REQUEST_FAILED", identifier: "ollama_request_failed", }, ]) ); }
for await (const chunk of getOllamaResponse(ollamaResponse)) { stream.write(createTextEvent(chunk)); }
stream.write(createDoneEvent()); } catch (error) { console.error("Error:", error); stream.write( createErrorsEvent([ { type: "agent", message: error instanceof Error ? error.message : "Unknown error", code: "PROCESSING_ERROR", identifier: "processing_error", }, ]) ); } });});Smart Context Handling#
The extension leverages GitHub Copilot’s context-passing capabilities to access file contents and other contextual information. Here’s how it works:
export function getUserMessageWithContext({ payload, type,}: { payload: CopilotRequestPayload; type: FileContext;}): string { const [firstMessage] = payload.messages; const relevantReferences = firstMessage?.copilot_references?.filter( (ref) => ref.type === `client.${type}` );
// Format context into markdown for Ollama const contextMarkdown = relevantReferences .map((ref) => { return `File: ${ref.id}\n${ref.data.language}\`\`\`\n${ref.data.content}\n\`\`\``; }) .join("\n\n");
return `${firstMessage.content}\n\n${ contextMarkdown ? `${FILES_PREAMBLE}\n\n${contextMarkdown}` : "" }`;}Setting Up Your Development Environment#
Prerequisites#
- Install and run Ollama locally
- Install the CodeLlama model:
Terminal window ollama pull codellama - Set up the extension:
Terminal window npm installnpm run dev
Exposing Your Extension#
To test the extension, make the web app’s port publicly accessible using one of these methods:
- VS Code port forwarding and set the port visibility to public; it’s private by default.
- cloudflared
- ngrok
Creating a GitHub App#
General Settings#
- Navigate to GitHub Developer Settings
- Create a new GitHub App with basic information
- Set appropriate URLs and callback endpoints
Permissions & Events#
- Configure Account permissions
- Set Copilot Chat and Editor Context to Read-only
- Save changes
Copilot Settings#
- Set App Type to Agent
- Configure public URL
- Save settings
Installation Steps#
- Navigate to GitHub Apps settings
- Install the app for your account
- Confirm installation
For the in depth instructions on how to do all of this, check out the Ollama Copilot extension’s development guide.
Using the Extension#
I’ve called my extension ollamacopilot but you can call yours whatever you want when running in development mode. When using a GitHub Copilot extension in Copilot chat, the prompt must always start with @ followed by the name of your extension and then your prompt, e.g. @ollamacopilot how would you improve this code?. Otherwise, Copilot chat will not call your extension.
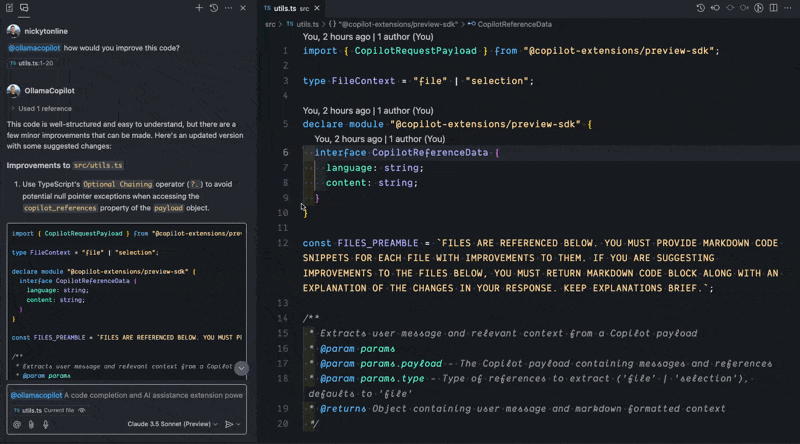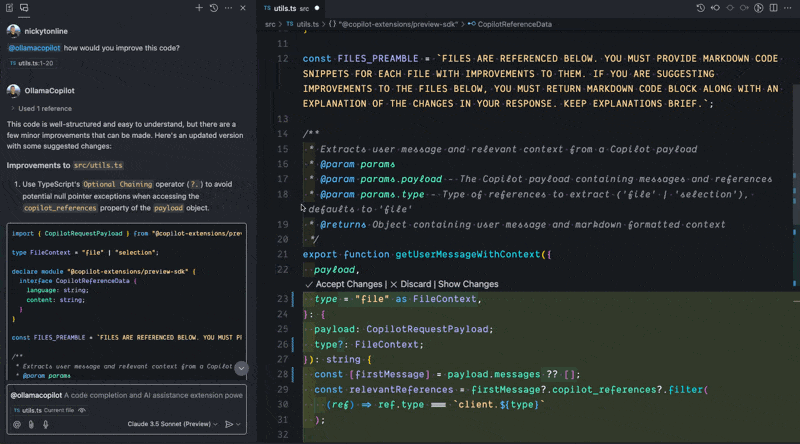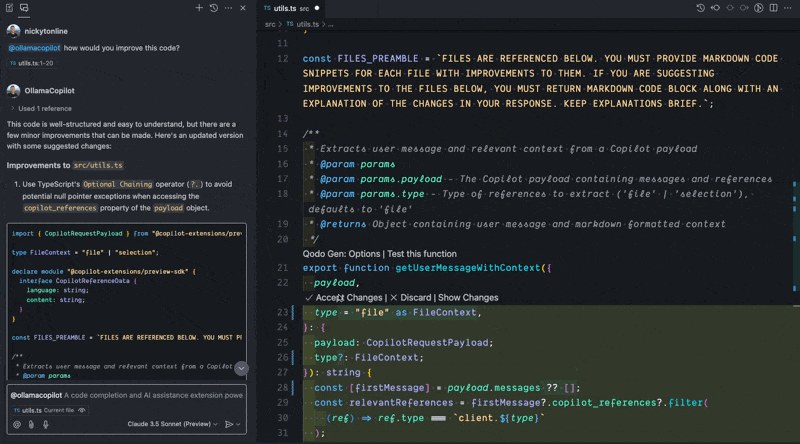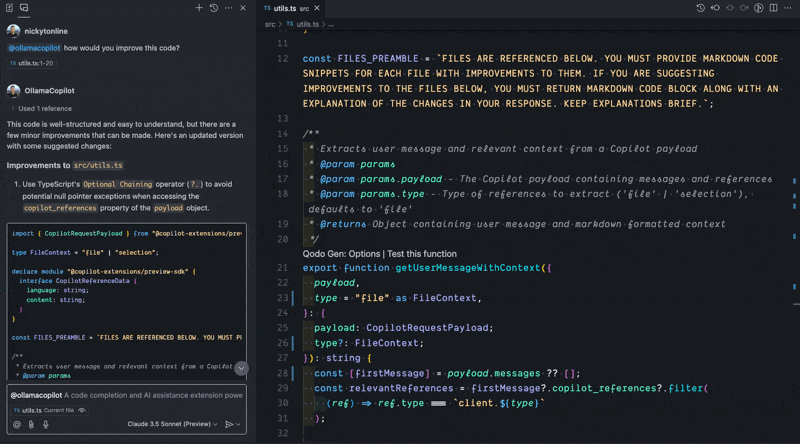
Current Limitations#
- Works only in local development environment at the moment
- Requires local Ollama installation
- Needs public Ollama API access for deployment
Future Possibilities#
- Multiple AI model support
- Context-aware coding suggestions
- Specialized development commands via slash commands
- expose Ollama securely on my local network so that I can use it anywhere
If I end up securing Ollama remotely, I’m probably going to use Pomerium for this on my local network. While Pomerium is known for its enterprise features, it’s also perfect for hobbyists and self-hosters who want to secure their personal projects. There are other options, but that’s what I’m going to go with.
One thing that this experiment has got me thinking is it’d be great if local Copilot extensions were a thing or if GitHub Copilot supported running local models. This wouldn’t work on GitHub.com or Codespaces, but would be viable for local development environments and still be valuable. I don’t think this would ever happen, but you never know.
Contributing#
Contributions are welcome! Feel free to open an issue to:
- Suggest new features & enhancements
- Improve documentation
- Report bugs
Wrapping Up#
I’m hoping to get this to a place where people can deploy the GitHub app for production, but at the moment, it is still super useful running it in development mode.
Get started by checking out the project on GitHub, and don’t forget to star it and the template it’s based on if you find it useful!
https://github.com/nickytonline/ollama-copilot-extensionUntil the next one peeps!
If you want to stay in touch, all my socials are on nickyt.online